





剪辑:Aeneas 好困hongkongdoll 视频
OpenAI第二天的直播,揭示了强化微调的强盛威力:强化微调后的o1-mini,居然全面超越了地表最强基础模子o1。而被奥特曼称为「2024年我最大的惊喜」的技能,技能阶梯竟和来自字节卓著之前公开发表的强化微调商议念念路相易。
OpenAI 12天连播的第二弹,用短短三个单词体现了什么叫「字少事大」——强化微调(Reinforcement Fine-Tuning)。
领先,这是OpenAI第一次将之前仅限自家模子(如GPT-4o和o1系列)使用的强化学习技能,怒放给外部开发者。
其次,开发者只需提供最低「几十个」高质料任务,就能通过强化微调已毕限制行家模子的定制!而且,还能笔据提供的参考谜底对模子的答谢进行评分。
终末,强化微调加强了模子在处理限制问题时的推理才能,并进步了在特定任务上的准确性。对于那些条目高精准性和专科常识的限制,强化微调将会阐述至关迫切的作用。
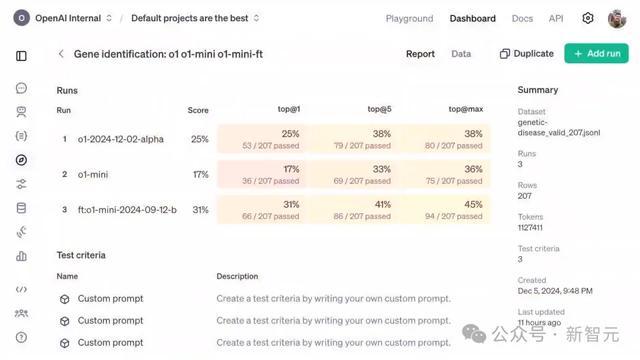
从OpenAI的官方演示中不出丑出,强化微调的恶果可谓是相配权臣——经过强化微调的o1 mini,居然全面超越了咫尺最强的基础模子o1。
其中,强化微调版的o1 mini,在Top-1准确率上径直跃升180%达到了31%,远超o1的25%。
对此,奥特曼欢乐地暗示:「这项责任恶果罕见得好,是我2024年最大的惊喜之一!相配期待各人会用它去构建什么。」
咫尺,强化微调商议规画已插足Alpha阶段,并将于2025年第一季度公开发布。

为了搞明晰「强化微调」到底是个啥,咱们便去问了问OpenAI自家的AI搜索。
没猜测,为止却出东说念主预感——这个技能念念路,在一篇被ACL 2024委派为Oral的论文中,就仍是提议了。
而更喜东说念主的是,团队的成员全部来自字节卓著!

在这项责任中,商议东说念主员提议了一种节略而灵验的才能,来自增强LLM推理时的泛化才能——强化微调(Reinforced Fine-Tuning,ReFT)。

论文地址:https://arxiv.org/abs/2401.08967
节略来说,ReFT领先会使用SFT对模子进行预热,然后选拔在线强化学习(PPO算法)进行优化。
也即是,对给定的问题自动采样多量的推理旅途,并笔据果然谜底来得回奖励,从而进一步对模子进行微调。
在GSM8K、MathQA和SVAMP数据集上的多量践诺标明,ReFT权臣优于SFT,而且通过长入多数投票和再行排序等战术,不错进一步进步模子性能。
不仅如斯,ReFT还有着非凡的泛化才能——在锤真金不怕火中仅需使用与SFT相易的问题集,而无需依赖极度或增强的锤真金不怕火数据。
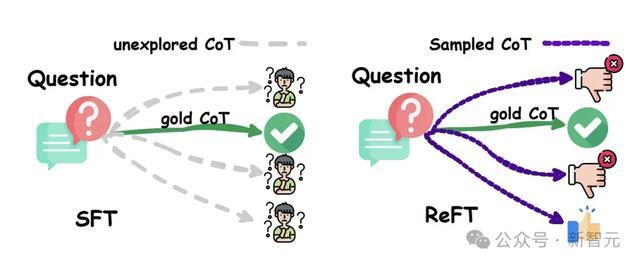
强化微调,不是传统微调
此次上阵直播的四东说念主,是OpenAI的商议员Mark Chen、John Allard、Julie Wang,以及伯克利践诺室蓄意生物学家Justin Reese。

他们先容说,这项功能已允许用户在我方的数据集上微调o1。
不外要强调的是,并不是传统的微调,而是强化微调。它真确诈欺了强化学习算法,把模子从高等中学水平进步到行家博士级别。
这个功能,粗略匡助把我方的优质数据集转念为惟一无二的用品,带来「魅力」。
强化微调(RFT),能让路发者、商议东说念主员和机器学习工程师初度有契机使用强化学习来创建行家级模子hongkongdoll 视频,真实 勾引在特定限制的任务中有非凡进展。
对于法律、金融、工程、保障等限制,这项技能几乎是量身打造的。
例如来说,OpenAI最近和汤森路透谐和,诈欺强化微调对o1 Mini进行了微调,使其成为了别称法律助手,帮法律专科东说念主士完成了一些复杂、需要深化分析的责任过程 。
史上初度,OpenAI微调复古强化学习
客岁岁首,OpenAI就推出了监督微调API。这项技能相配强盛,中枢方向是让模子复制在输入文本或图像中发现的特征。
在强化微调中,它不仅是教模子师法输入,而是去学习在自界说域上以全新的形态进行推理。
当模子看到一个问题,商议者会给它空间来念念考问题,然后给它的最终谜底进行评分。
然后,诈欺强化学习的强盛才能,他们会强化那些导致正确谜底的念念维旅途,同期阻难那些导致失误谜底的念念维旅途。
只需要数十到数千个高质料示例,模子就能学会以新的、灵验的形态在定制限制中进行推理了!
用OpenAI商议者的话说,这委果太跋扈了,令东说念主难以置信——仅用12个例子就能作念到,这是传统微调难以已毕的。
这亦然史上初度,OpenAI的模子定制平台不错复古强化学习。
商议者强调说,OpenAI里面用来锤真金不怕火GPT-4o和o1系列等顶尖模子,即是用的相通技能。
强化微调的o1,会诊稀薄病
伯克利践诺室的Justin,就先容了强化微调给他的商议带来的纷乱匡助。

他商议的是,使用蓄意才能来意会稀薄疾病背后的遗传原因。
但是,现在评估稀薄疾病并谢绝易,领先要对医学有专科限制常识,还要对生物医学数据进行系统化推理。
而这,o1模子不错凭借其高等推理才能提供匡助。
在这个名目中,Justin和共事们从数百篇对于稀薄疾病的科学病例论说中索要了疾病信息,包括患者的体征和症状。
他们但愿能笔据患者的症状,找出可能发生突变、导致这些症状的基因。
为此,他们和OpenAI团队一齐锤真金不怕火了o1模子,让它更高效地推理疾病的成因。
而在「笔据一系列症状揣测可能激励遗传疾病的基因」这一任务上,o1-mini的进展超越了o1!
这相配迫切,因为o1-mini比o1更小、更快、资本更低。
在OpenAI的开发平台上,他们仍是对一个模子进行监督微调一年多了。
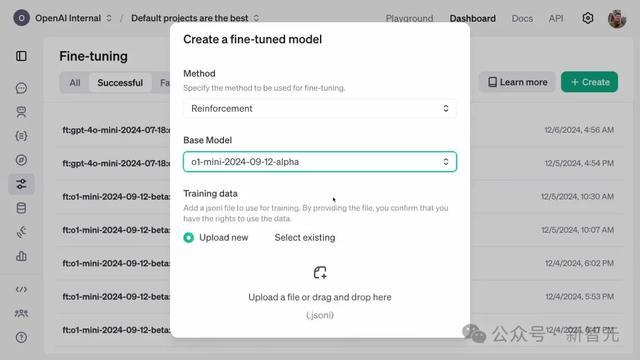
他们上传了一个锤真金不怕火数据集,包含1100个示例。
以下是一个单独的数据点,包括病例论说、指示、正确谜底三个部分。
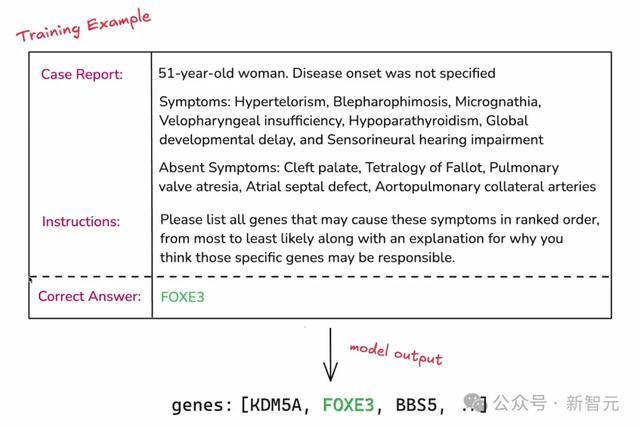
病例论说表现,这是别称51岁的女性,有眼距增宽、甲状旁腺功能亢进等症状。在指示部分,商议者会指示模子,但愿它作念什么。终末即是正确谜底。
留意,锤真金不怕火过程中,并不会向模子展示这个谜底,不然即是舞弊了。
但是,商议者以这锤真金不怕火过程顶用这个谜底来评估模子。
不错看出,这个任务的难度,仍是远远超越了「Strawberry中有几个r」的级别。
接下来,他们上传了一些考证数据,它的形势与锤真金不怕火数据透顶相易,但考证数据集和锤真金不怕火数据集之间的正确基因莫得重迭。
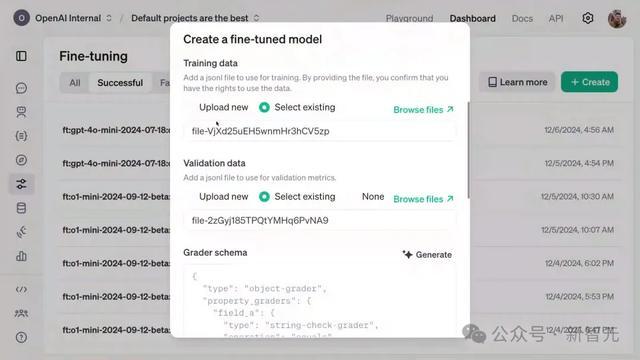
这就意味着,模子不可舞弊,不可只是节略地记着症状列表并将其与基因匹配。
它必须真确从锤真金不怕火数据集泛化到考证数据集。
强化学习的部分,是这么体现的——
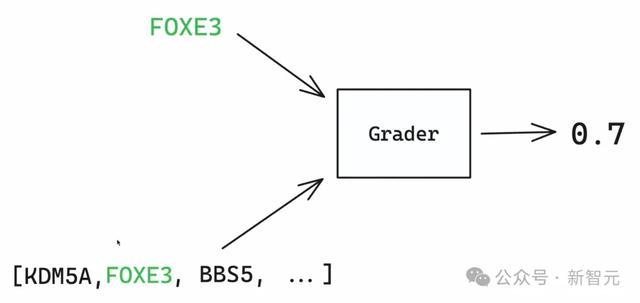
他们引入评分器的主见,将模子输出与正确谜底相比,复返0到1之间的一个分数。0暗示模子透顶失误,1暗示模子透顶正确。
情欲超市未删节版全集在这个例子中,模子得到了0.7的分数,因为FOXE 3是正确谜底,在基因列表中排第二位。
它在列表中越往后,分数会越接近0。
最终,商议者提供了一套评分器书籍,能灵验掩饰在强化微调时可能会有的各式意图空间。
接下来,不错快速地复制一下评分器,然后就启动了一个锤真金不怕火任务。
是非的场地在于,只需要提供数据集和评分器(体现限制专科常识),就不错诈欺OpenAI强化学习算法的全部才能,以及无缺的散播式模子锤真金不怕火技能栈,来为我方的使用场景定制一个前沿模子了。
一句话即是:拿上你的数据集和评分器,OpenAI就会给你一个微调模子。
强化学习微调任务可能需要几个小时到几天的时辰来启动
不错看到,考证集的奖励分数呈飞腾趋势。
由于锤真金不怕火数据集和考证数据集之间的基因莫得重迭,这意味着:模子如实学会了这项任务中进行泛化!
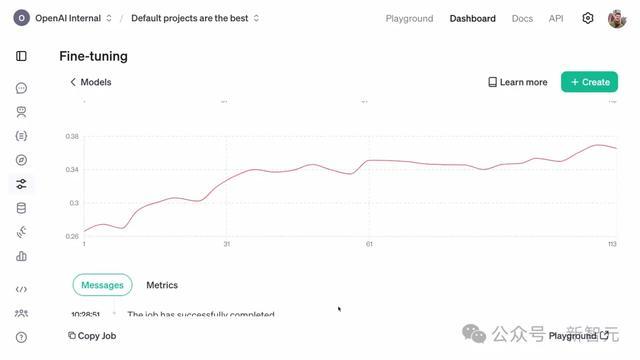
模子学领路用推理才能
为了更深化地了解模子中微调过程中发生了什么变化,不错张望评估样貌板。
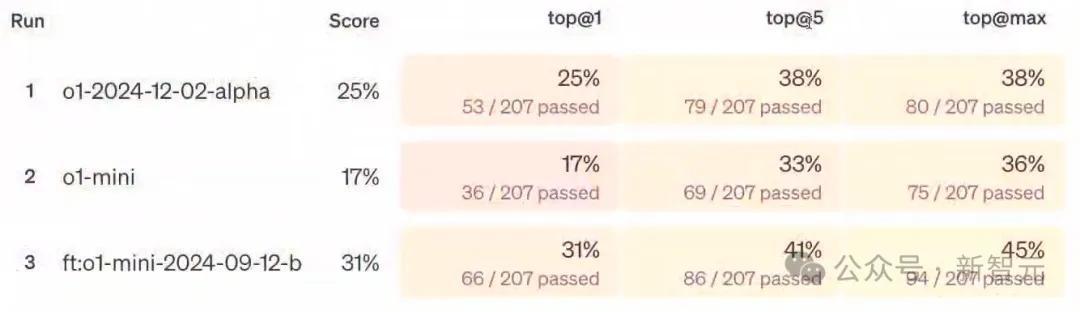
其中,商议者开荒了三个不同启动,分手是启动在o1、o1 mini和强化微调后的o1 mini上的任务。
不错看到,奖励分数呈现右上角飞腾的趋势,但这对任务来说意味着什么呢?
为此,他们开荒了三个不同的评估目的,分手是Top-1(第一项正确率)、Top-5(前五项正确率)和Top-max(是否包含正确谜底)。
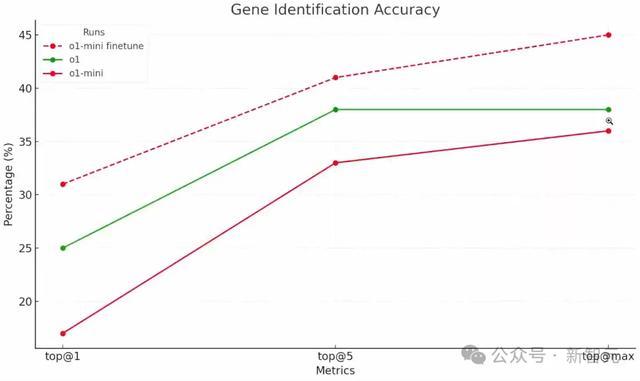
在Top-1目的中,o1 mini在约200条数据上的得分是17%。o1得到了25%,而微调后的o1 mini,得到了31%。
ChatGPT就此生成了一张更直不雅的图表。
这表现出,模子如实学会了如安在这类数据上进行推理的通用才能!
在Justin看来,强化学习将极地面激越生物学商议社区,近期内的最好决策,可能即是长入现存生物信息学器用和类o1模子的夹杂措置决策。
而以上,只是是强化微调在科学商议中的一个应用辛勤。
除了已训导证的生升天学、AI安全、法律以及医疗保健数据集,模子还会在数百种其他应用场景上阐述作用。
OpenAI的Alpha规画,会让更多东说念主在最迫切的任务上,股东o1模子才能的范畴。
直播终末,依然是OpenAI式的圣诞冷见笑一则——
最近,圣诞老东说念主在尝试制造一辆无东说念主驾驶雪橇,但不知为何,他的模子老是无法识别树木,导致雪橇束缚地撞上说念路两旁的树。你们猜这是为什么?
谜底是:因为他忘了给模子进行「pine-tune」(松树微调)!
